Sparse Index中的数据指针
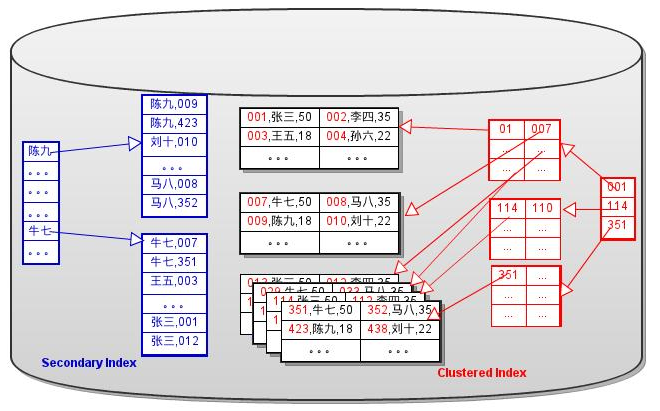
Sparse Index中的每个键值都有一个指针指向所在的数据页。这样每个B+Tree都有指针指向数据页

如果数据页进行了拆分或合并操作,那么所有的B+Tree都需要修改相应的页指针。特别是Secondary B+Tree, 要对很多个不连续的页进行修改。同时也需要对这些页加锁,这会降低并发性。为了降低难度和增加更新(分裂和合并B+Tree节点)的性能,InnoDB 将 Secondary B+Tree中的指针替换成了主键的键值
接下来看一下数据操作在B+Tree上的基本实现。
用主键查询
直接在Clustered B+Tree上查询。
用辅助索引查询 A. 在Secondary B+Tree上查询到主键。 B. 用主键在Clustered B+Tree上查询到数据。

可以看出,在使用主键值替换页指针后,辅助索引的查询效率降低了。
A. 如果能用主键查询,尽量使用主键来查询数据。B. 但是由于Clustered B+Tree包含了完整的数据,遍历的效率比 Secondary B+Tree的效率低。如果遍历操作不涉及到二级索引和主键以外的数据,则尽量使用二级索引进行遍历。
INSERT
- 在Clustered B+Tree上插入一条记录
- 在所有其他Secondary B+Tree上插入一条记录(仅包含索引字段和主键)
DELETE
- 在Clustered B+Tree上删除一条记录。
- 在所有Secondary B+Tree上删除二级索引的记录。
UPDATE 非键列
- 在Clustered B+Tree上更新数据。
UPDATE 主键列
- 在Clustered B+Tree删除原有的记录(只是标记为DELETED,并不真正删除)。
- 在Clustered B+Tree插入一条新的记录。
- 在每一个Secondary B+Tree上删除原有的记录。(有疑问,看下一节。)
- 在每一个Secondary B+Tree上插入一个条新的记录。
UPDATE 辅助索引的键值
- 在Clustered B+Tree上更新数据。
- 在每一个Secondary B+Tree上删除原有的记录。
- 在每一个Secondary B+Tree上插入一条新的记录。
更新键列时,需要更新多个页,效率比较低。
A. 尽量不用对主键列进行UPDATE操作。 B. 更新很多时,尽量少建索引。Clustered B+Tree优先选择列:
- 含有大量非重复的列
- 新增内容太过离散随机的列
- 返回大量结果集的查询
不建议的聚集索引:
- 修改频繁的列
- 新增内容太过离散的随机列
糟糕的主键选择:
- UUID CHAR/VARCHAR DATATIME/TIMESTAMP
索引优点
- 加快数据检索效率
- 可以创建唯一性约束索引,保证表中每一行数据的唯一性
- 加速表和表连接效率
- 在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间
索引缺点
- 索引需要占用更多物理存储空间
- 当表中的数据进行增加,删除和修改的时候,索引也要更新维护,降低数据维护效率
那些情况下建议创建索引
- 经常需要搜素的列
- 作为主键的列,有唯一约束索引
- 经常表连接的列
- 经常需要排序/分组的列
那些情况下不建议创建索引
- 很不经常被搜素的列
- 基数值很低的列
- 长text/blob类型列
- 唯一性差的列 不建议创建索引 查询条件很少出现的列
设计原则
- 低选择性的列不加索引,如性别;
- 常用的字段放在前面;选择性高的字段放在前面;
- 需要经常排序的字段,可加到索引中,列顺序和最常用的排序一致;
- 对较长的字段数据类型优先考虑前缀索引如index(url(64));
- 只创建需要的索引,避免冗余索引,如index(a,b)index(a)。
索引的限制
- 只支持B+tree,hash索引不支持bitmap;
- 不支持表达式,函数索引;
- 不支持全模糊匹配;
- Innodb索引最大支持768字节,myisam索引最大支持1000字节;
- 超过30%的扫描比例时,直接走全索引扫描;
- Blob和text类型的列只能创建前缀索引;
- Join语句中join字段类型不一致的时候MySQL无法高效实用索引。
##本文学习索引主要摘自MySQL代码研究微信号公共号